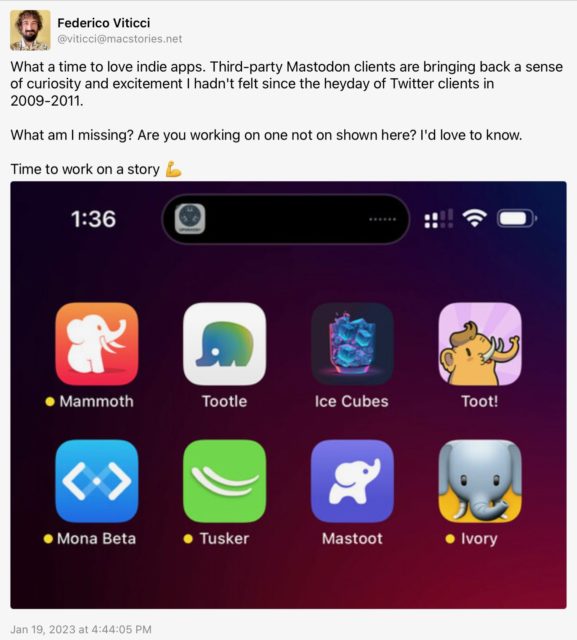
Back in January I wrote a post titled “What Mastodon Needs”, about what I felt were the most serious shortcomings of that social media platform after I’d been on it for a couple of months. (Some of those issues have been resolved by my settling on Ivory as my Mastodon client, but others remain stubbornly unresolved, joined by new ones such as a lack of quote-reposts.)
I thought it’s time to write one on the other would-by Twitter replacement platform I spend some time on, Bluesky.
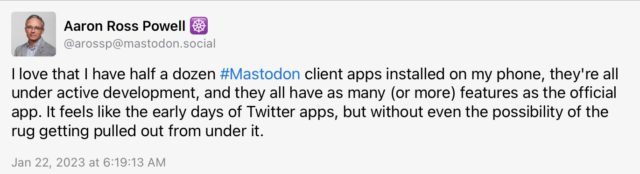
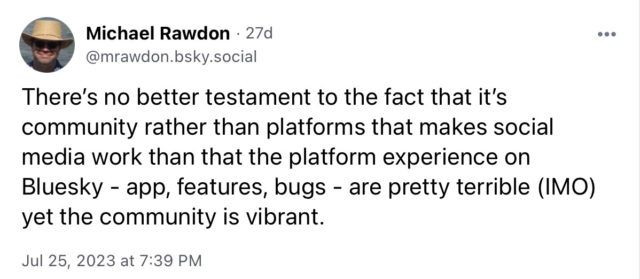
Full transparency: I find Mastodon a lot more useful and enjoyable than Bluesky. But many people are the other way around. Indeed, when I see someone compare the two, it’s almost always in Bluesky’s favor. Last month I made the following observation:
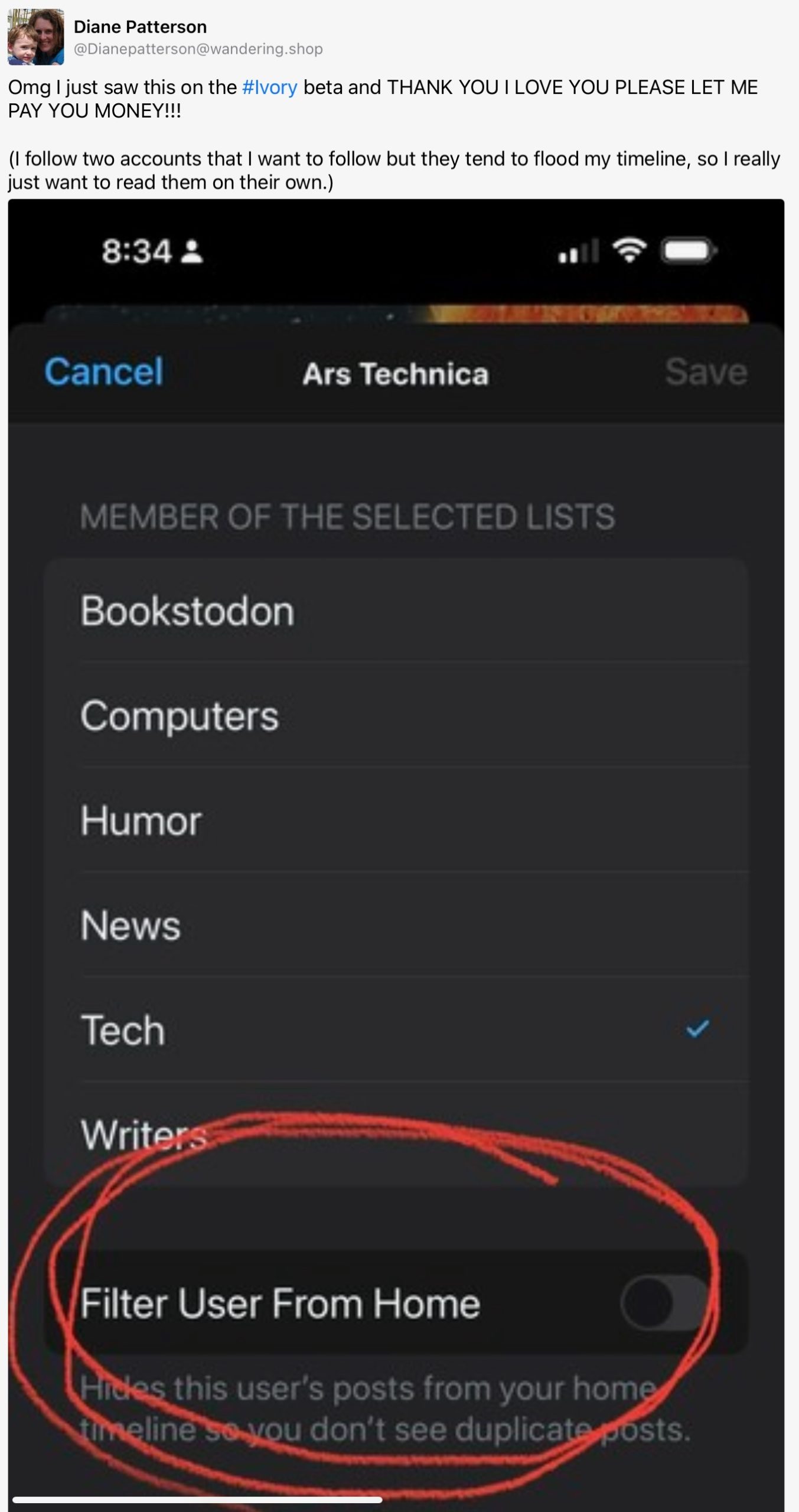
There are also people who have found Mastodon to be a mixed-to-negative experience. I could pull a number of examples, but here’s a particularly prominent one from today:


All of this is fair enough. And Bluesky does have a few significant detractors, often people with problems with its ownership. Which is also fair enough. After all, I’m not on Threads because I don’t really want to get deeper into the Facebook ecosystem.
Anyway, my main goal here is to hit major points of usability where I feel Bluesky is lacking. And I should be clear that I realize that Bluesky is a platform which is still in beta (indeed, it feels like it’s not quite ready for beta and I suspect it opened up before it had planned to), is still invitation-only (only users with invite codes can invite new users), and reportedly has very small development team. So I expect progress will be slow, and it’s starting from a point of being much less mature than Mastodon.
So here we go:
1. Lists: I’ve been an avoid user of lists on both Twitter and Mastodon. I have a dozen or more lists which I use to divide up accounts I follow by category, saving my main timeline for accounts I either want to check in with whenever I check in on the platform, or which don’t fall into a category. But, for example, I put most Magic: The Gathering accounts, or audio drama accounts, into their own list. And I remove them from my main timeline. (This last point is something neither Twitter nor Mastodon supports natively, I think, but some apps like Tweetbot did and Ivory does.)
Not having lists is likely to impose a strong cap on how many accounts I follow. This isn’t an issue yet (I’m following only 39 accounts – Bluesky is still small, folks), but it will be if the site gets popular.
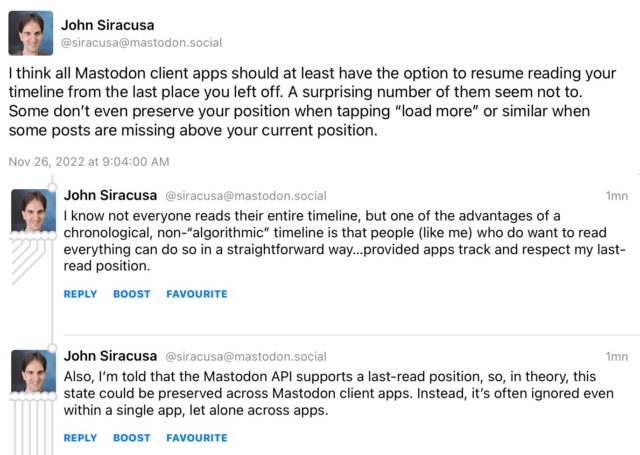
2. Remembering my reading position: This was a bullet point for Mastodon, and it’s a problem on Bluesky, too.
3. An iPad app which doesn’t suck: Presently the iPhone app runs on the iPad in compatibility mode, which is frankly pretty lousy – especially because it’s pretty buggy and its UX is not very polished. Instagram also has the problem of no native iPad app, but it’s not as much of an issue there because Instagram is image-centric.
4. Disabling reposts per-user: Some people repost a lot. Which is fine – people can do with their accounts what they want. But I find being able to disable reposts for a few users significantly improves my experience on social media, when I enjoy the personally-written posts by those users but mostly find their reposts to be a fire hose of things which are way more important to them than to me. Right now my only option is to mute them entirely (which I have done a couple of times).
Related to this is being able to mute a user (or a keyword!) for a day, a week, or a month, since sometimes people get focused on something which is time-bound which doesn’t interest me, but once that time is passed I want to resume following them.
These are little things that Twitter and/or its third party clients provided which turned out to be indispensable to enjoying it in the long run.
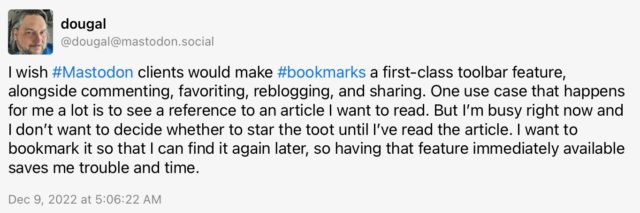
5. Bookmarks and a way to see your Likes: Mastodon has both Likes and Bookmarks. Bluesky has Likes but no Bookmarks, and as far as I can tell there’s no way to view a list of the posts you’ve Liked.
6. Hashtag support: This would be a more useful way to find like-minded people and posts than Bluesky’s feed system, which my experience with so far has found it to be pretty clunky.
The other big problem is one I think all social media sites going forward will have: Fragmentation of communities. The tech community is mostly on Mastodon, the science fiction and comic book communities are on Bluesky, and the Magic: The Gathering and audio drama communities are still very sticky on Twitter (or, as I like to call it after its X rebrand, Shitter). There probably isn’t a “solution” to this, it just means that people like me who follow multiple communities will need to be on multiple platforms.
Anyway, Bluesky does have a fair bit of fun stuff happening (and not all of it revolving around Neil Gaiman, John Scalzi and Popehat), it’s just that the platform itself makes it difficult for me to interact with. I hope it gets better, but I’m not going to hold my breath for that to happen.